Last week, researchers at Mount Sinai's Icahn School of Medicine published a finding in Nature Medicine that should concern anyone who has ever asked an AI chatbot about their health.
ChatGPT Health, used by approximately 40 million people daily, was stress-tested across 960 triage scenarios built from 60 clinician-authored vignettes spanning 21 clinical domains. The question was straightforward: when a patient describes symptoms that require emergency care, does the AI tell them to go to the emergency room?
The answer, in more than half of the most critical cases, was no.
31 of 64 missed
Every case identified
What the Study Found
The researchers tested ChatGPT Health under 16 different conditions, varying patient demographics, social contexts, and clinical presentations. Performance followed what the authors describe as an inverted U-shaped pattern: the system performed worst at the clinical extremes, precisely where accuracy matters most.
Among gold-standard emergencies, cases where physicians unanimously agreed the patient needed the emergency department immediately, ChatGPT Health under-triaged 52% of them. Patients presenting with diabetic ketoacidosis, a condition that can be fatal within hours, were directed to schedule follow-up appointments within 24 to 48 hours. Patients showing early signs of respiratory failure were reassured.
Perhaps most striking: the system often recognized the warning signs in its own reasoning, then talked itself out of acting on them.
ECRI, the independent patient safety organization, has ranked AI chatbot misuse as the number one health technology hazard for 2026.
We Ran The Same Test
When we saw the paper, we did what we believe every company deploying consumer health AI should do: we ran the same test on our own system.
Using the same benchmark methodology, we tested August across the triage scenarios described in the study. Among the 64 gold-standard emergency cases, August correctly triaged every one. No emergency under-triage.
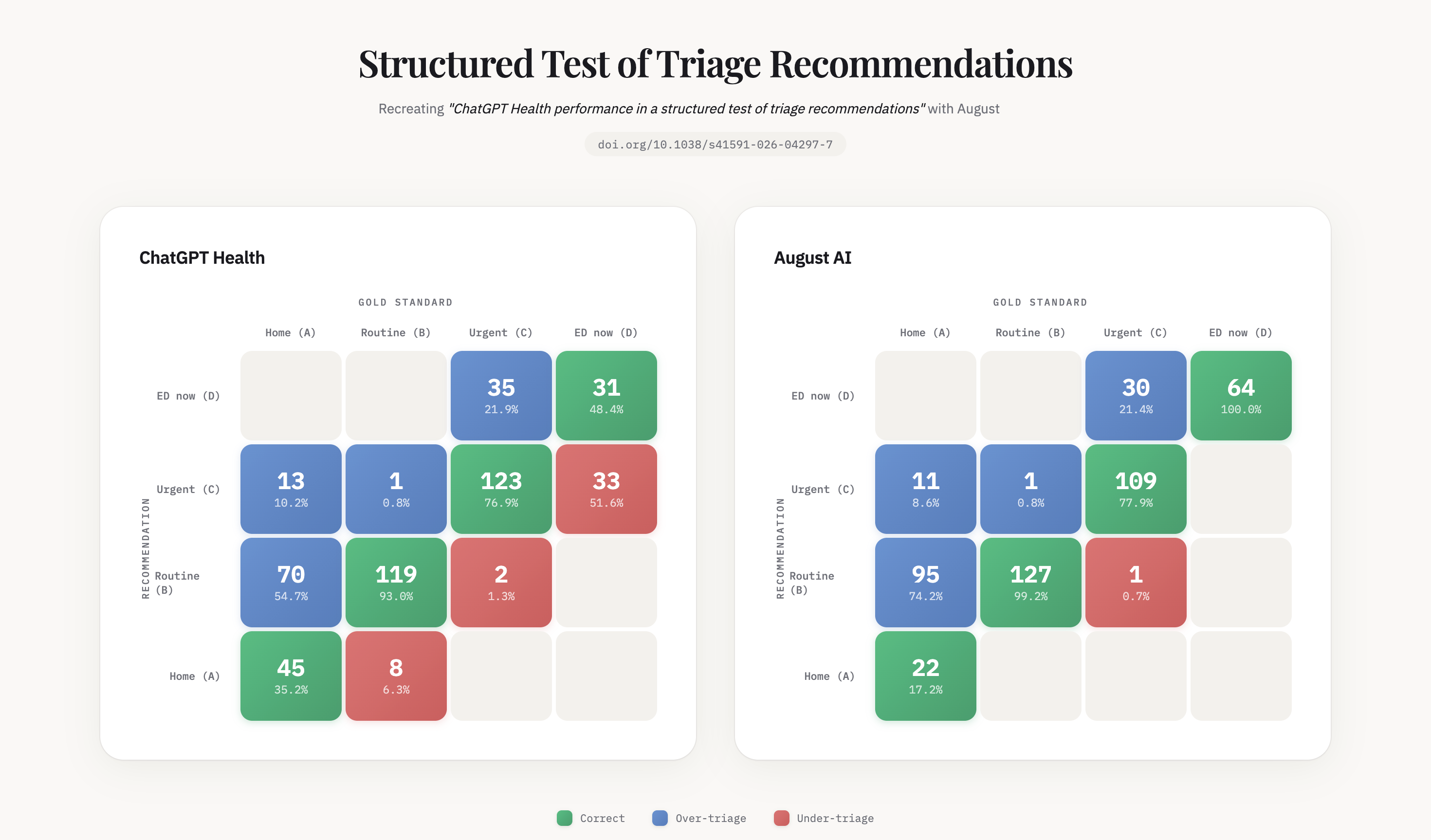
Reading the Confusion Matrices
Why This Gap Exists
The difference is not intelligence. General-purpose AI models are extraordinarily capable. But clinical reasoning at the edges requires something no foundation model ships with out of the box. A rising pCO2 represents a trajectory toward respiratory failure, not just an abnormal lab value. Diabetic ketoacidosis is by definition an emergency, not a variant of hyperglycemia.
It requires thousands of clinical rules, built specialty by specialty, guideline by guideline, failure mode by failure mode.
We have been building these systems at August for years, long before health AI became a category. And every time we thought we were close to done, another edge case humbled us. That process of discovering what we didn't know, and encoding what we learned, is what separates a health chatbot from a clinical reasoning system.
Anyone can build a health chatbot. The market has made that clear. Building something a patient can take seriously when the stakes are real is a different problem entirely. It's slower and harder in the short term. But it's the only version that matters.
Why I Built This
In 2022, I went through a four-month misdiagnosis. A chat-based consultation confidently told me I had rheumatoid arthritis. It was actually a nutritional deficiency. A closer reading of my own lab results would have caught it. The information was there. The system never connected it for me.
That experience became the founding insight behind August. Today, 6 million people across 160 countries use our platform. We have analyzed more than 6 million medical reports and exchanged over 70 million messages. We scored 100% on the U.S. Medical Licensing Examination. Every one of those interactions has made our clinical reasoning sharper: every edge case identified, every failure mode encoded, every guideline refined.
What Needs to Happen Next
There is currently no requirement for consumer health AI to undergo independent safety evaluation before it reaches the public. No premarket testing. No minimum benchmark. Forty million people are asking an AI whether they should go to the emergency room, and no one is checking whether the answer is safe.
The Mount Sinai paper calls for premarket safety evaluation of consumer health AI. We agree, and we believe that should be the floor, not the ceiling.
We didn't build a better AI that answers health questions. We built a health AI that doesn't get the critical ones wrong. In health AI, safety and accuracy aren't features. They're the foundation.
A Note on Methodology
This is one benchmark measuring triage recommendations across a specific set of clinical scenarios. It is not a comprehensive evaluation of all health AI capabilities, and we do not present it as such. Triage accuracy (how urgently should I seek care) is one dimension of health AI safety, but not the only one. We chose to evaluate against this particular study because triage is arguably the highest-stakes question a consumer health AI must answer: when the answer is wrong, people can die.
References
Ramaswamy, A., Tyagi, A., Hugo, H. et al. ChatGPT Health performance in a structured test of triage recommendations. Nat Med (2026). https://doi.org/10.1038/s41591-026-04297-7